transformer
一、背景
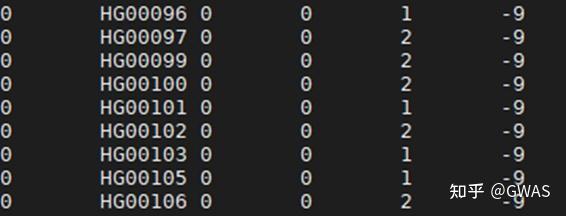
1. 序列到序列模型
1)语音辨识
输入输出关系:输入声音信号(t帧特征向量),输出对应文字(n个字),t与n无固定比例关系。
典型案例:台语语音辨识系统(1500小时乡土剧训练数据)。
技术特点:直接端到端训练,跳过音标转换等中间步骤(”硬train一发”方法)。
2)机器翻译
长度关系:输入句子长度n与输出句子长度n’由模型动态决定。
中英案例:“机器学习”(4字)→”machine learning”(2词),非固定1/2比例(可长可短)。
3)语音翻译(语音辨识复合机器翻译)
特殊价值:适用于无文字语言(全球7000+语言中过半无文字系统)。
实现方式:直接建立语音到目标语言文字的映射,避免传统ASR+MT串联方案。
4)台语语音辨识应用案例
数据来源:YouTube乡土剧(台语音频+中文字幕对齐数据)。
技术挑战:背景⾳乐/噪声干扰(直接忽略处理);字幕与语音不完全对齐(仍可训练);跳过台罗拼音中介步骤(端到端训练);强行训练。
典型错误:倒装句处理困难(”我有帮厂长拜托” vs 正确应为”我拜托厂长”);语义理解偏差(”要生了吗” vs 正确答案”不会腻吗”)。
5)台语语音合成应用案例
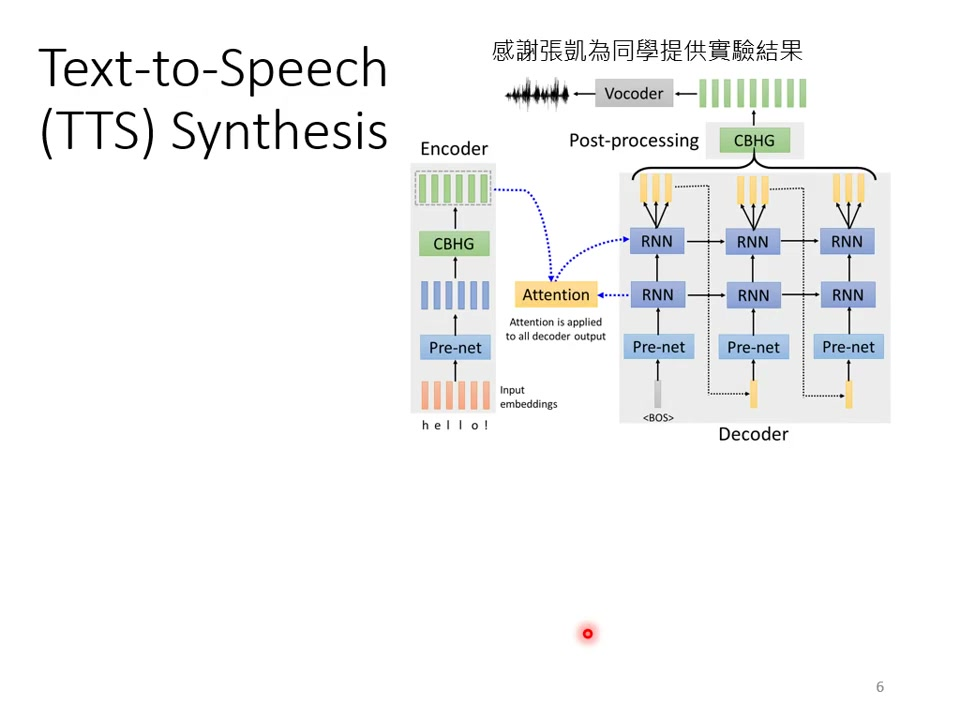
实现方案:两阶段处理:中文→台罗拼音→声音信号;使用Tacotron模型(基于Seq2seq架构)。
合成示例:“欢迎来到台大语音处理实验室”→台语发音。
6)聊天机器人
训练数据:影视剧对话数据集(输入-响应配对)。
实现方式:将对话建模为[输入语句→响应语句]的序列转换任务。
7)自然语言处理

统一视角:多数NLP任务可视为QA问题:翻译:问题=”英文句子的德文翻译?”;摘要:问题=”文章的摘要是什么?”;情感分析:问题=”句子是正面/负面?”。
实现方案:将”问题+上下文”拼接作为输入序列,答案作为输出序列。
2. 任务应用
1)多标签分类
核心区别:多分类任务:从多个类别中选择一个最合适的类别(n选1);多标签任务:一个对象可以同时属于多个类别(n选k,k不固定)。
应用示例:文章分类中,一篇文章可能同时属于”科技”和”教育”两个类别;图片标注中,一张图片可能包含”猫”、”狗”、”草地”等多个标签。
传统方法局限:直接取分类器得分前三名会失效,因为不同样本的标签数量可能不同(有的需要2个标签,有的需要3个)。
Seq2Seq解决方案:让模型自主决定输出序列长度(即标签数量);输入文章,输出不定长的类别序列(如:Class1 Class3)。
2)目标检测
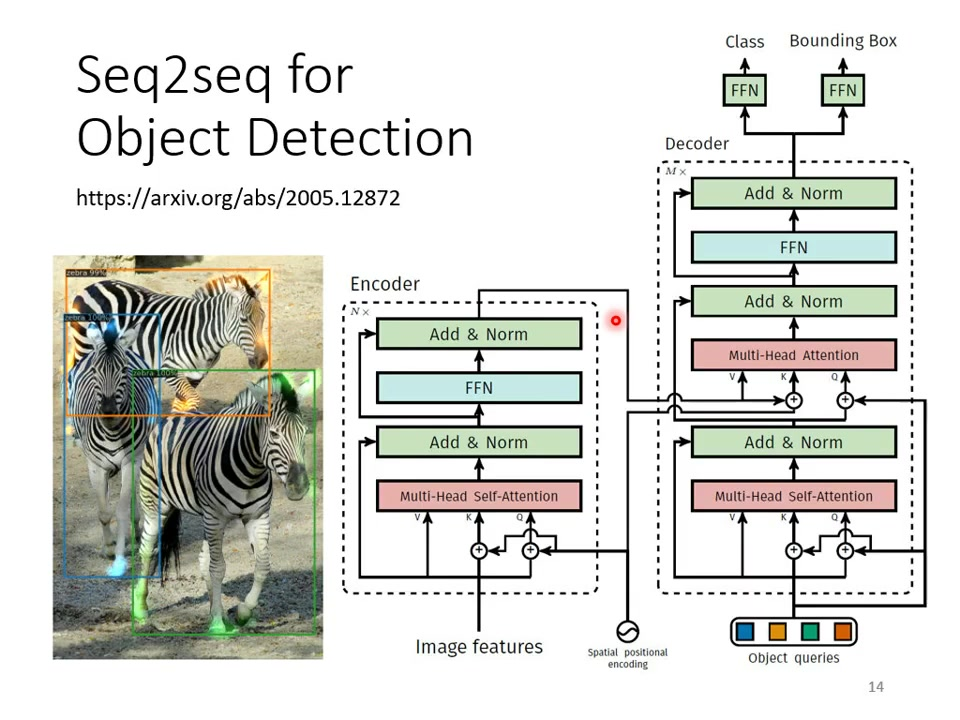
创新应用:传统目标检测需要预定义anchor boxes;Seq2Seq模型可以直接输出检测结果序列。
实现特点:输入图片特征,输出不定长的(object class, bounding box)序列;模型自主决定需要检测的物体数量。
参考文献:DETR模型论文链接:https://arxiv.org/abs/2005.12872。
二. transformer结构
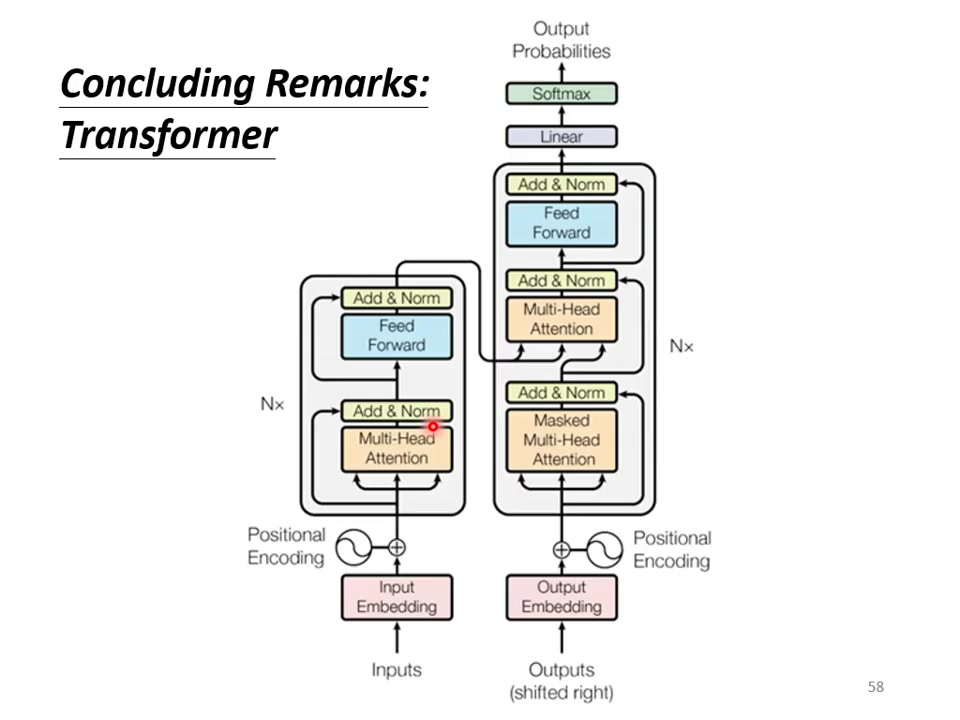
1.编码器
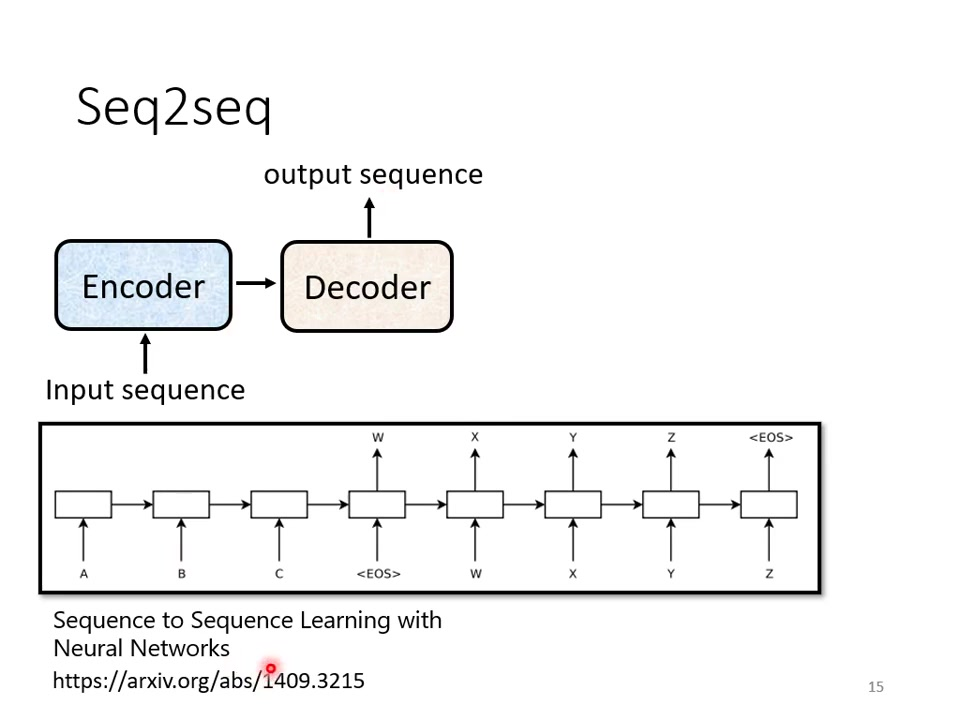
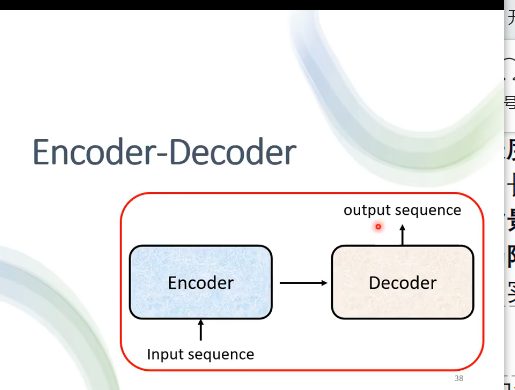
组成结构:Encoder:处理输入序列,输出中间表示;Decoder:基于编码结果生成输出序列。
发展历程:2014年首次提出(论文:https://arxiv.org/abs/1409.3215);现以Transformer架构为主流。
1)编码器的block
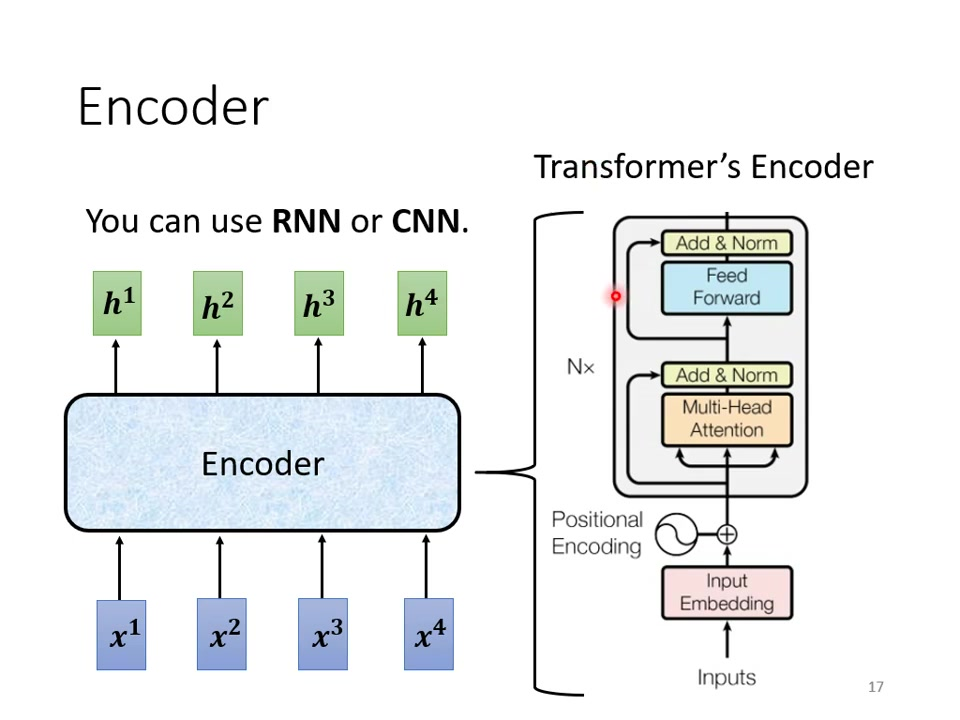
基本流程:输入向量序列通过多个相同结构的block;每个block包含:Multi-head Self-attention层、Feed Forward层、残差连接和Layer Normalization。
2)位置编码
必须添加positional encoding来保留序列顺序信息;与输入embedding相加后送入encoder。
3)自我注意力的层次
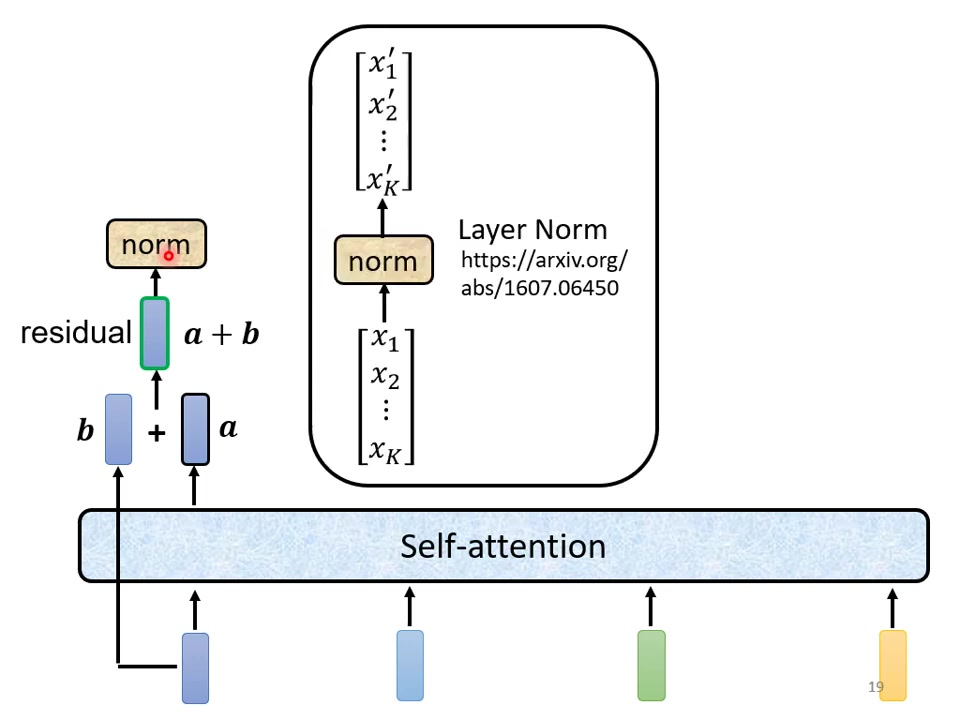
残差连接:将self-attention层的输入直接加到输出上(a + b);缓解深层网络梯度消失问题。
Layer Normalization:对单个样本的所有维度计算均值方差;公式:[图像];与Batch Norm区别:不依赖batch统计量。
完整流程:Self-attention + 残差;Layer Norm;[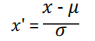 ][图像];FFN + 残差;再次Layer Norm。
][图像];FFN + 残差;再次Layer Norm。
架构优化:原始设计非最优(论文:https://arxiv.org/abs/2002.04745);调整normalization位置可能提升性能;PowerNorm可作为Layer Norm替代方案(论文:https://arxiv.org/abs/2003.07845)。
2.解码器
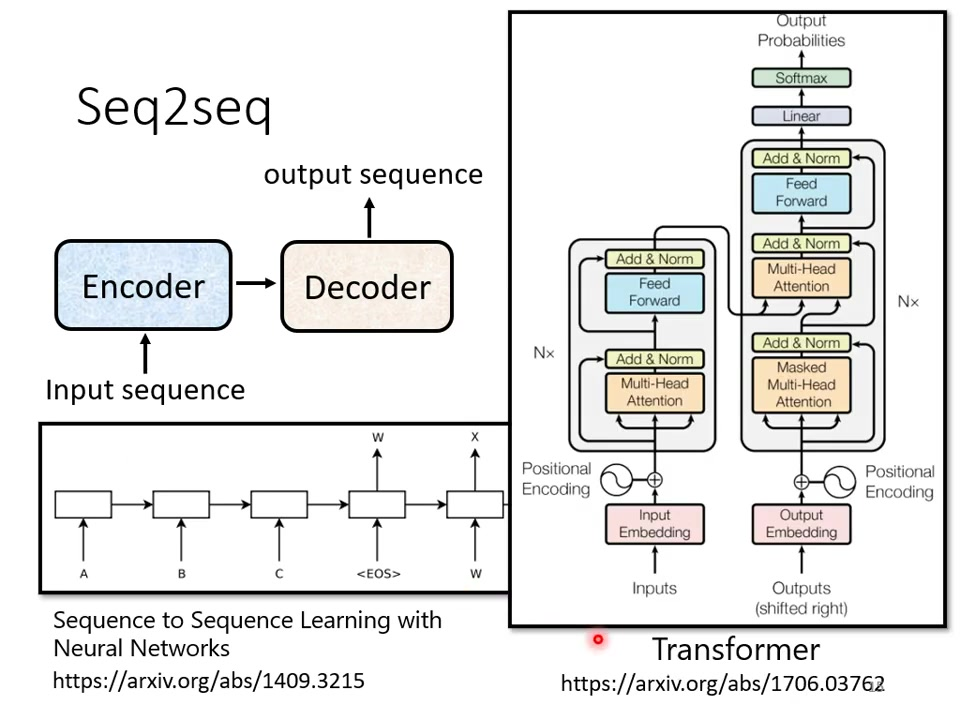
1) 自动回归解码器
1.1 例题:语音识别
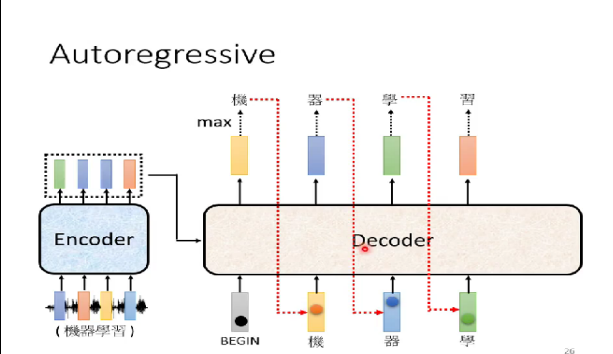
工作原理:输入声音信号(如”机器学习”的语音),通过encoder转换为vector sequence,decoder逐步生成文字输出。输入输出转换与机器翻译原理相同,只需改变输入输出内容(语音→文字 vs 文本→文本)。特殊起始符需在decoder输入中加入BEGIN符号(BOS),用one-hot vector表示(某一位为1其余为0)。
输出向量特性:输出向量长度等于vocabulary size(如中文常用3000字),经softmax处理后形成概率分布(总和为1),输出的就是中文的每一个字的可能性,比如预测下一个字之后可能输出的方块字的可能性。多语言处理差异:英文可选择字母/单词/subword为单位,中文通常以单个方块字为单位,英文是以词或者字母,或者词组。中文是单个字进行输出。输出的是一个分布。分数最高的中文字就是最终的输出。
decoder的上一个输出回合以前的输入成为新的decoder的输入。自己的输出当作下一个时间的自己的输出。
1.2 解码器的结构
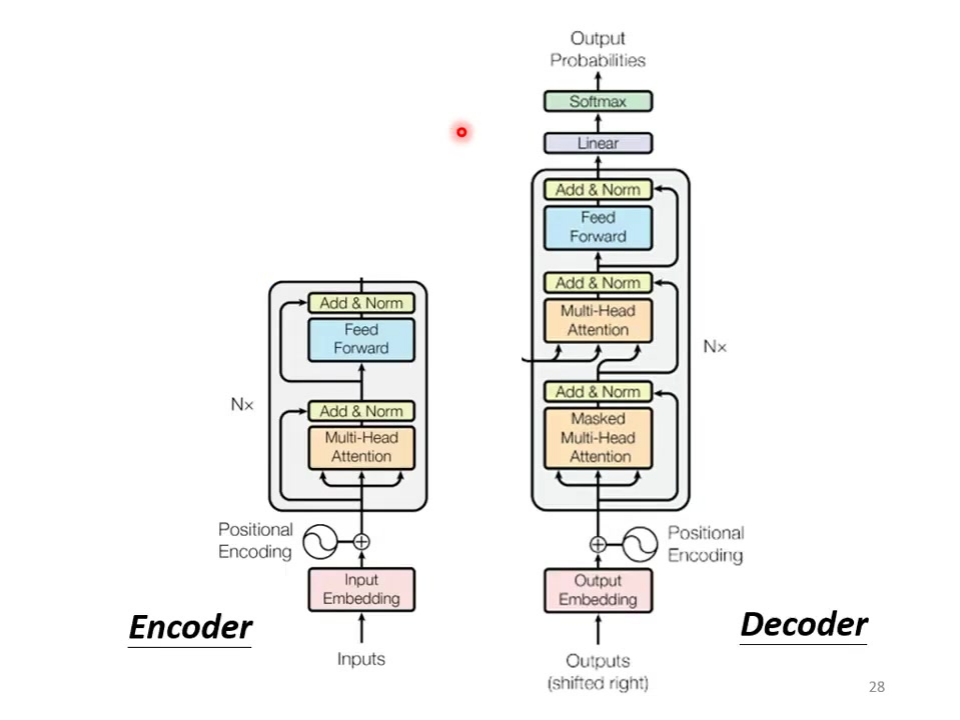
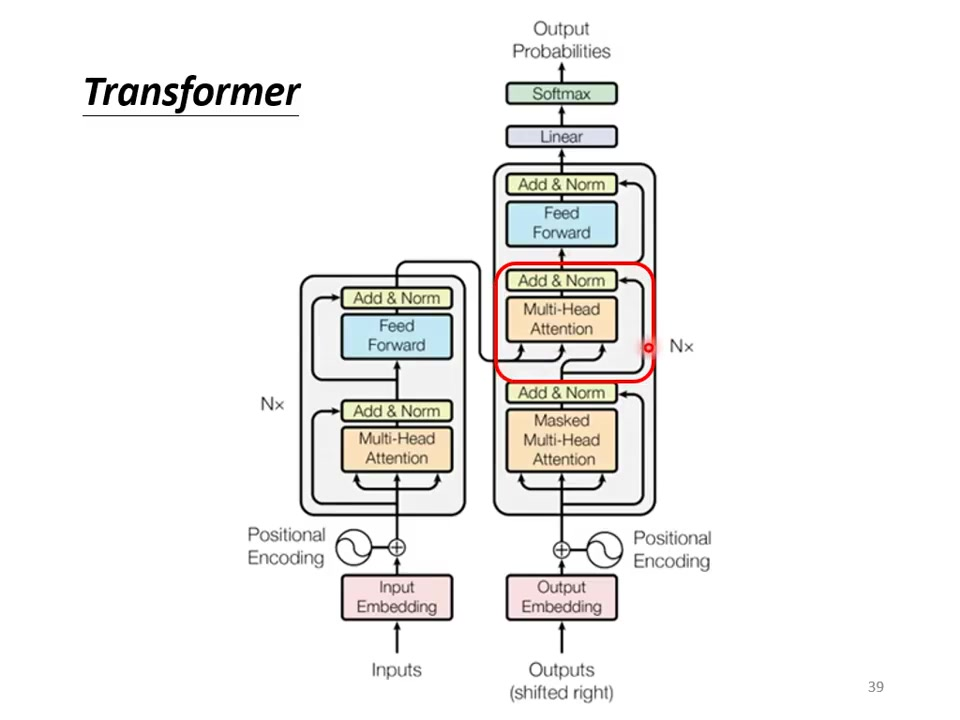
基础结构:与encoder相似(multi-head attention → add & norm → feed forward → add & norm),重复N次。
关键差异:输出端增加softmax层生成概率分布(输出变成未来的几率);采用masked multi-head attention(屏蔽未来信息)包含中间特殊连接层(图中被遮盖部分)现在不能再去看未来的信息了。
自回归特性:将前步输出作为当前输入(如BEGIN→”机”→”器”→”学”→”习”),输入和输出的结果长度不确定。
错误传播风险:若中间输出错误(如将”器”误为”气”),后续输出可能持续错误。
1.3 屏蔽自我注意
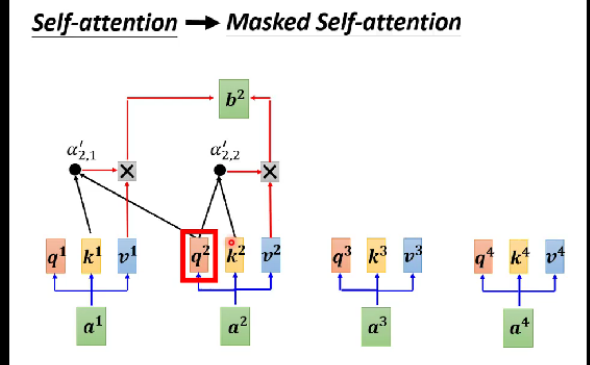
对应的query和key不会涉及到之后的信息,是有顺序的。
屏蔽原理:计算bi时只能关注a1到ai,禁止访问右侧信息(ai+1及之后)。
实现方式:计算attention时,query只与左侧key相乘(如q2只与k1,k2计算);通过设置attention score为-∞实现右侧屏蔽。
必要性:decoder输出具有时序性(a1→a2→…),生成ai时无法知晓ai+1信息
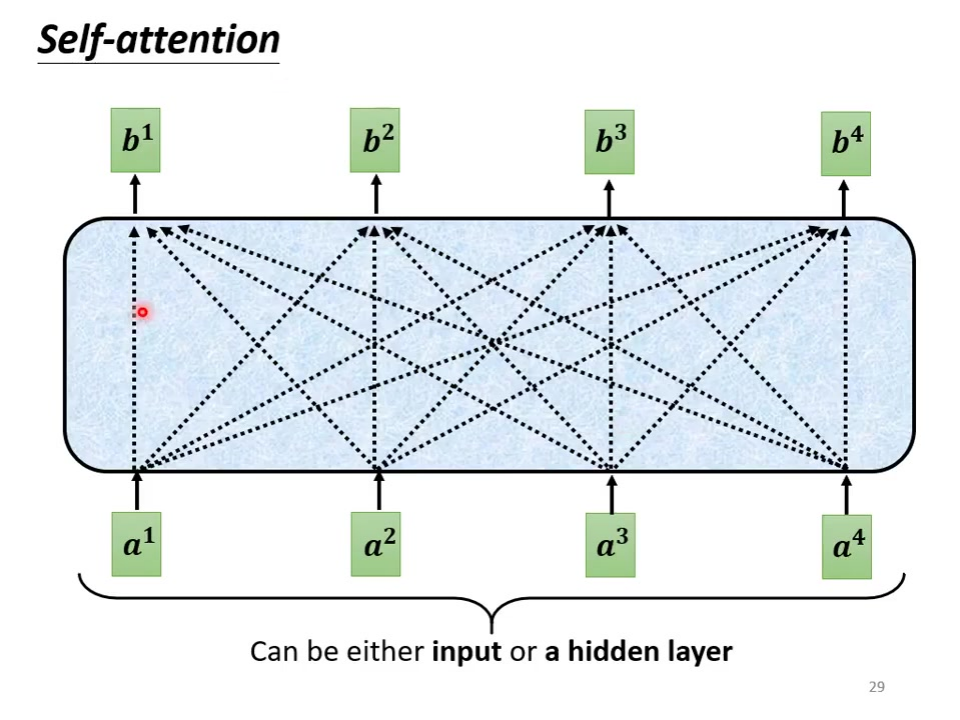
对比标准attention:原始self-attention可同时访问全部输入信息。
1.4 输出序列长度确定
例题:推文接龙类似于成语接龙。

类比说明:类似PTT推文接龙(如”超→人→正→大→中→天”),需明确终止机制。
持续风险:若无终止信号,decoder可能无限生成输出(如”机器学习习习习…”)。
停止标记:特殊符号在vocabulary中添加END标记(与BEGIN可同符号)有开始就要有结尾
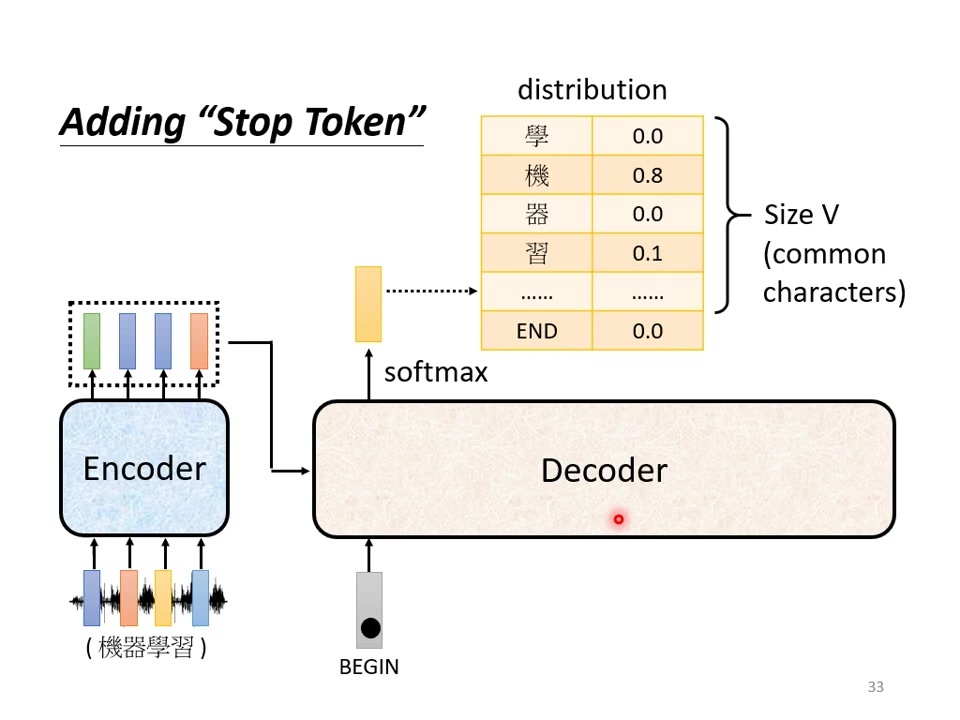
终止条件:当输出END的概率最大时停止生成。
实现细节:训练时让decoder学习在适当位置输出END;中文处理时需额外增加该特殊符号(超出常规汉字集)。
工作流程:完整生成过程示例:BEGIN→”机”→”器”→”学”→”习”→END,产生习之后END的概率应该最高。
2) 非自动回归解码器
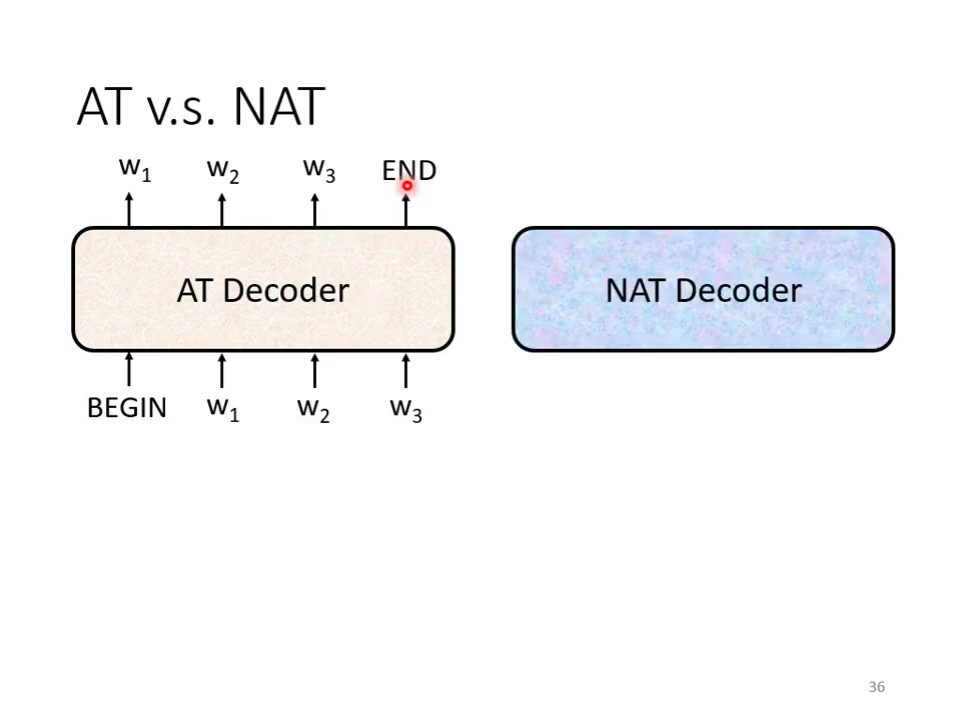
AT工作方式:采用自回归方式(Autoregressive),缩写为AT。依次生成序列:输入BEGIN→输出W1→将W1作为新输入→输出W2→…→直到输出END标记。不是一次产生的。
NAT工作方式:非自回归(Non–autoregressive)模型,缩写为NAT。一次性生成整个序列:输入一排BEGIN token→直接输出完整序列(如中文句子)。
长度控制方法:使用分类器预测输出长度:分类器读取encoder输出,预测数字n→decoder接收n个BEGIN token,简单的预测一个对应的长度;
预设最大长度:输入固定数量BEGIN token(如300个),通过END标记截断多余输出,假设一个具体长度的上限。
2.1 非自动回归解码器的优点
并行计算优势:无论输出长度多少都只需一个计算步骤,速度显著快于AT(100字句子AT需100次计算,NAT只需1次)计算步骤明显减少。输出长度
可控性:通过调整预测长度的分类器输出,可精确控制生成速度(如语音合成中,长度×2→语速减半)。
技术背景:依赖Transformer的self-attention机制,传统RNN/LSTM无法实现此架构
当前局限:存在multimodality问题,性能通常低于AT模型,需复杂技巧才能达到相近效果,实际上准确度很差,很多的研究只能逼近对应的AT模型。
3)编码器和解码器之间的连接
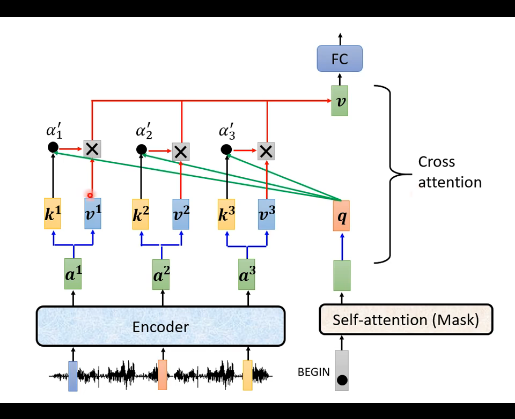
信息传递方式:通过cross attention(桥梁)连接,decoder生成query(q),encoder提供key(k)和value(v)。
具体流程:encoder输出向量a1,a2,a3转换为k1,k2,k3和v1,v2,v3;decoder输入(如BEGIN)生成query(q);计算q与k的attention分数,加权求和v得到输出向量。
层级连接:原始方案中所有decoder层都使用encoder最后一层输出,但可自定义其他连接方式,可以由操作者自行定义,永远可以有新的想法。
4) 训练
4.1 需要什么样的训练资料
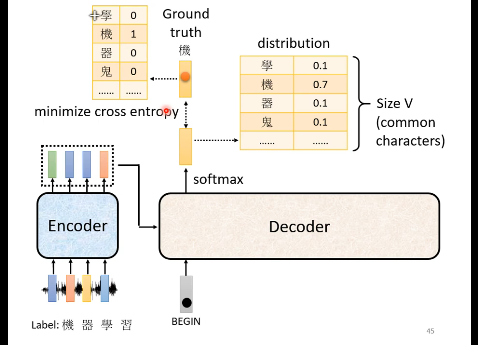
数据要求:输入序列(如音频)与对应输出序列(如人工标注文本)的配对数据。
标注格式:每个输出token对应one-hot向量(如4000个中文单字的分类问题),每一个输出都有一个交叉熵,所有的交叉熵的总和越小越好。
4.2 训练过程
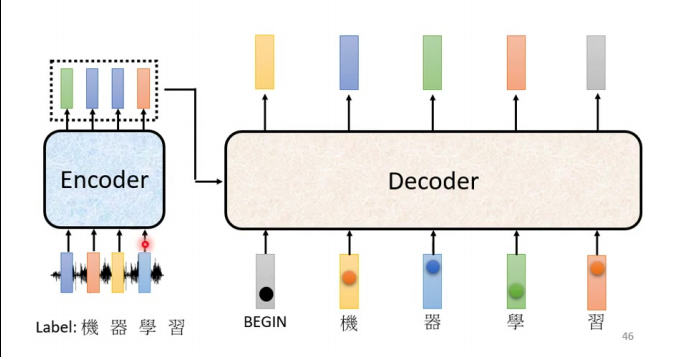
Teacher Forcing:训练时decoder接收真实序列作为输入(BEGIN+正确答案),测试时使用自身输出,训练的时候会给decoder看正确答案。
损失计算:每个时间步计算输出分布与one-hot向量的交叉熵,总和最小化。特殊标记处理:需包含END标记的训练(如4字句子需计算第5个位置的END损失)。
训练-测试差异:存在exposure bias问题,后续可能需用计划采样(scheduled sampling)等方法缓解。
5) 训练技巧
5.1 复制机制
5.1.1 复制机制在任务中的应用
核心思想:允许decoder从输入序列中直接复制内容到输出,而非完全自主生成。
适用场景:当输出内容部分或全部存在于输入中时特别有效,如专有名词、特定术语等(聊天机器人)。
必要性:对于罕见词汇(如”库洛洛”),模型可能从未在训练数据中见过,自主生成困难。
5.1.2 聊天机器人中的复制机制举例
案例1:输入:”你好,我是库洛洛”;理想输出:”库洛洛你好,很高兴认识你”;机制优势:模型无需生成罕见词”库洛洛”,只需学习复制模式”我是[某某某]→[某某某]你好”。
案例2:输入:”小杰不能用念能力了”;理想输出:”你所谓的不能用念能力是什么意思”;机制优势:直接复述用户输入中的关键短语,避免生成错误。
5.1.3 摘要任务中的复制机制
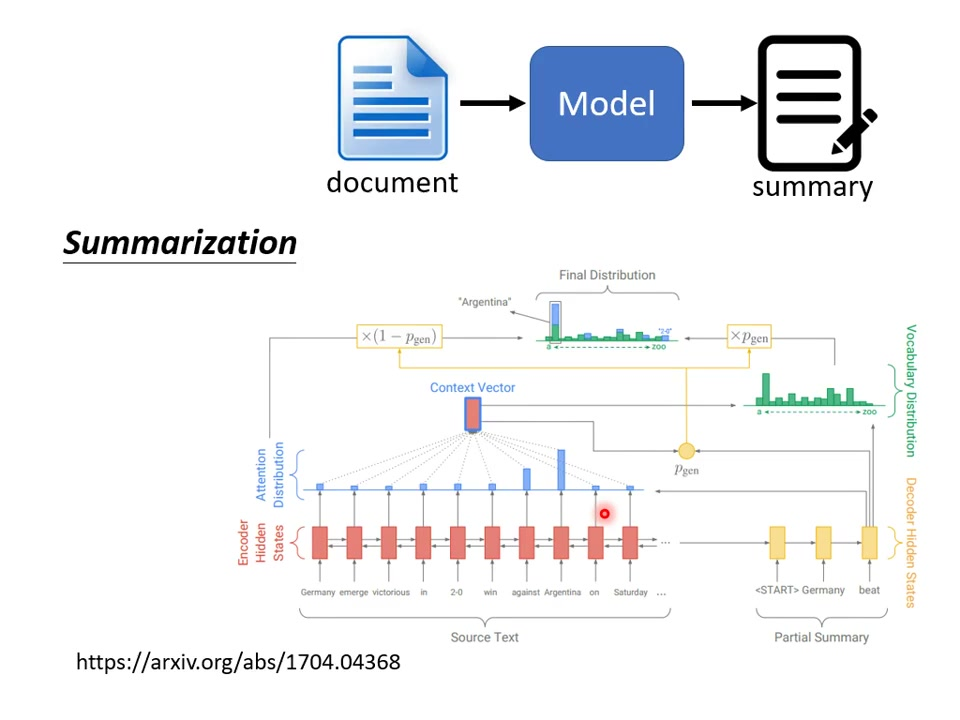
数据需求:需要百万级文章-摘要配对数据(几万篇效果不佳)。
复制必要性:摘要中60-70%内容通常直接来自原文;
类似人工摘要过程:筛选关键句+改写。
训练技巧:可利用文章标题作为摘要简化标注。
5.1.4 实现复制机制的模型
Pointer Network:最早实现复制能力的模型。
Copy Network:改进版本,论文《Incorporating Copying Mechanism in Sequence-to-Sequence Learning》。
实现原理:通过概率pgen决定生成新词或复制输入词。
5.2 引导注意
5.2.1 Sequence to Sequence模型在语音合成中的应用
典型应用:输入文字→输出语音波形。
成功案例:输入:”发财发财发财发财”(四次);输出:自动添加抑扬顿挫。数据需求:需要大量文本-语音配对数据。
5.2.2 Sequence to Sequence模型的局限性
漏字问题:输入:”发财”(单次);错误输出:”财”(漏掉”发”)。原因分析:短句训练数据不足导致处理异常。
5.2.3 Guided Attention的引入与重要性
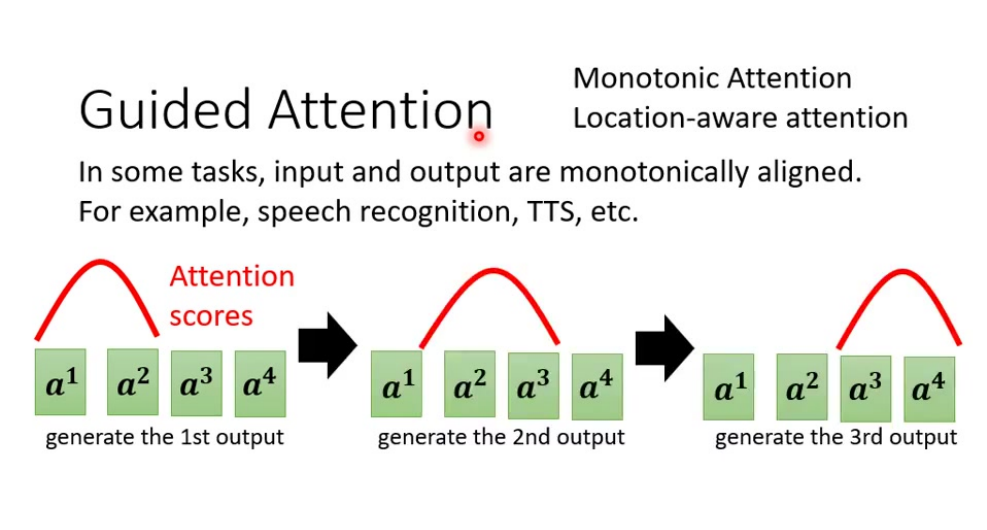
核心思想:强制模型按特定模式处理输入。
关键应用:语音识别:必须听完整个输入;
语音合成:必须读完所有文字。必要性:相比聊天机器人等任务,语音任务对完整性要求更严格。
5.2.4 Monotonic Attention与Location-aware Attention简介
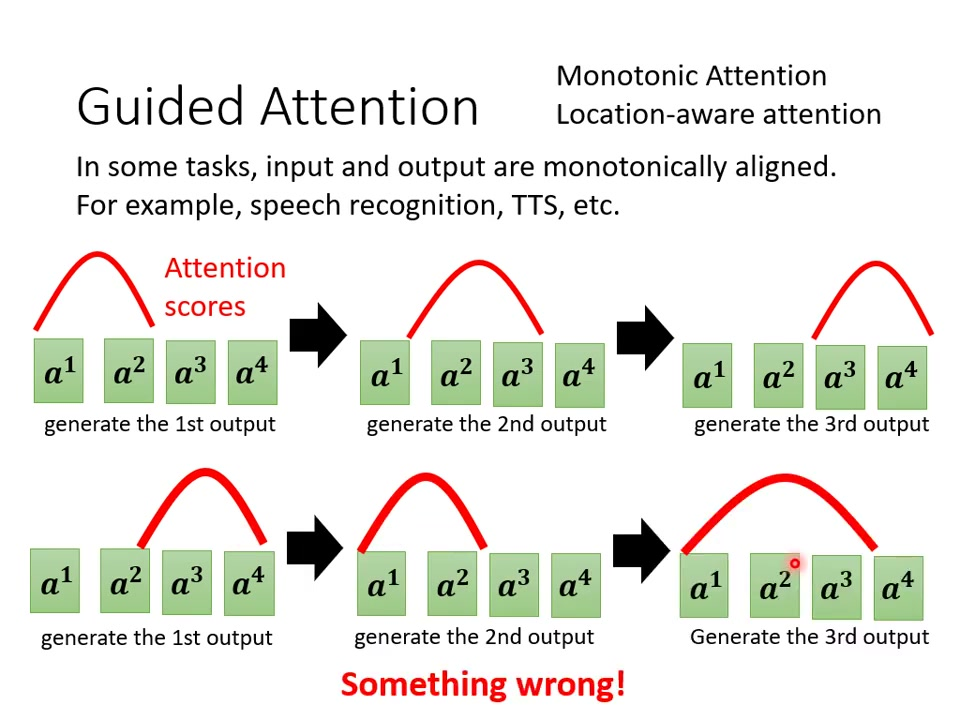
Monotonic Attention:强制注意力从左到右移动;适合语音合成等单调对齐任务。
Location-aware Attention:考虑当前位置信息;防止注意力”颠三倒四”。实现效果:通过约束注意力路径解决漏字问题。
5.3 束搜索
5.3.1 贪婪解码(Greedy Decoding)介绍
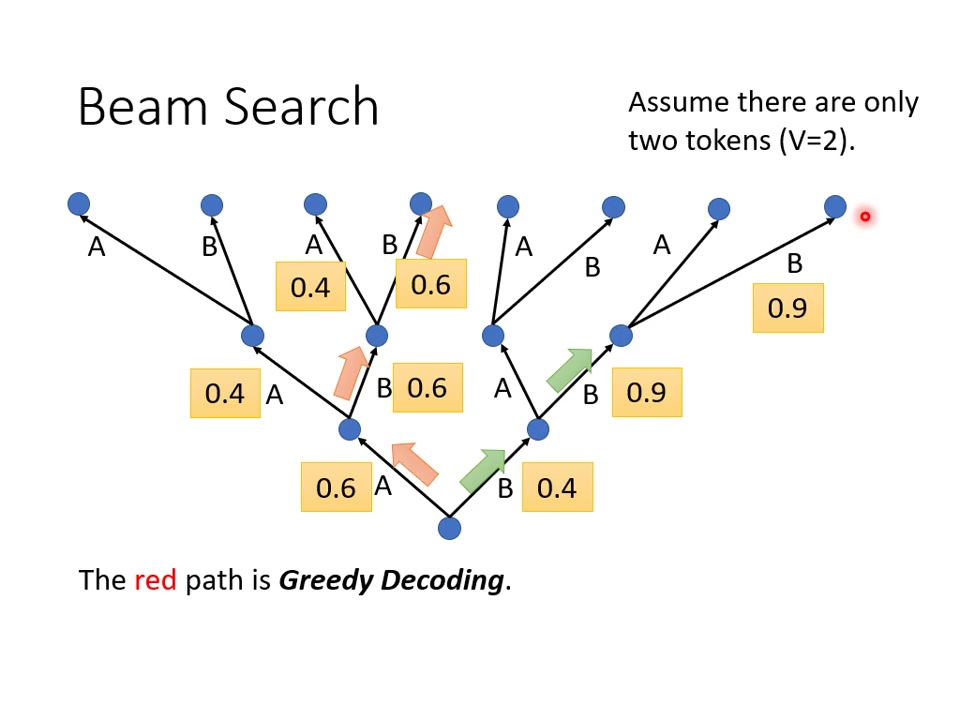
工作原理:在每一步解码时选择当前概率最高的token(max选择),如示例中第一步选择概率0.6的A,第二步选择0.6的B,最终输出序列为ABB。
局限性:可能陷入局部最优,如红色路径虽然每个步骤都选最大值,但整体序列概率(0.6×0.6×0.6=0.216)低于绿色路径(0.4×0.9×0.9=0.324)。
5.3.2 束搜索与贪婪解码的对比
策略差异:贪婪解码只保留单一路径,而束搜索(Beam Search)保留Top B(束宽)条路径,通过牺牲短期收益可能获得更优全局解。
类比说明:类似”天龙八部珍珑棋局”中先牺牲局部棋子获得全局胜利,或人生决策中短期辛苦(如读博)可能带来长期收益。
5.3.3 束搜索的必要性
计算可行性:当词表大小V=4000时,3步解码就有4000³种路径,穷举不可行。束搜索通过束宽B控制计算复杂度。
折中方案:不是精确求解而是近似搜索,平衡计算资源和结果质量。
5.3.4 束搜索的效果评价
适用场景:语音识别等答案明确的任务效果较好,因其需要确定性输出。
潜在问题:在需要创造力的任务(如文本生成)中可能导致重复输出(如”鬼打墙”现象)。
5.4 采样
5.4.1 任务介绍:句子合成(Sentence Completion)

任务特点:给定前半句生成后半句,存在多种合理续写方式,属于开放式生成任务。
5.4.2 Beam Search的问题:重复与无穷循环
典型表现:如论文案例中机构名称”Universidad Nacional…”的无限重复,输出失去语义连贯性。
5.4.3 随机性在Decoder中的作用
必要性:通过引入采样噪声(如top-k/top-p采样)打破确定性输出模式,生成更自然的文本。
5.4.4 任务特性与采样策略的关系
确定性任务:语音识别等应采用Beam Search。
创造性任务:文本生成、故事续写等需引入随机性。
哲学启示:“接受不完美才是真正的美”(呼应神经网络输出不一定概率最高即最优)。
5.4.5 需要随机性的任务示例:语音合成(TTS)
反常现象:测试时加入噪声反而改善合成效果(正常ML应在训练时加噪)。
对比表现:纯确定性解码会产生机械的”机关枪式”语音,适当随机性使发音更自然。
5.5 优化评估指标
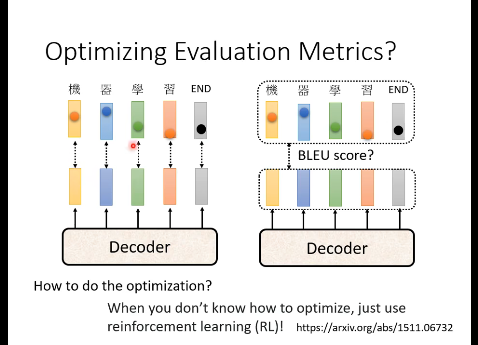
评估指标差异:训练时使用交叉熵损失(cross entropy),而评估时使用BLEU score,两者目标不一致。
指标特性对比:BLEU score需要生成完整句子后与参考答案进行整体比较;交叉熵对每个词汇分开计算损失。优化困境:BLEU score不可微分,无法直接用于梯度下降;
实际应用中通常选择BLEU score最高的模型而非交叉熵最低的模型。
解决方案:RL方法将BLEU score作为强化学习的reward,decoder作为agent;实践建议该方法实现难度较大,作业中不特别推荐使用。
5.6 训练与测试不一致的问题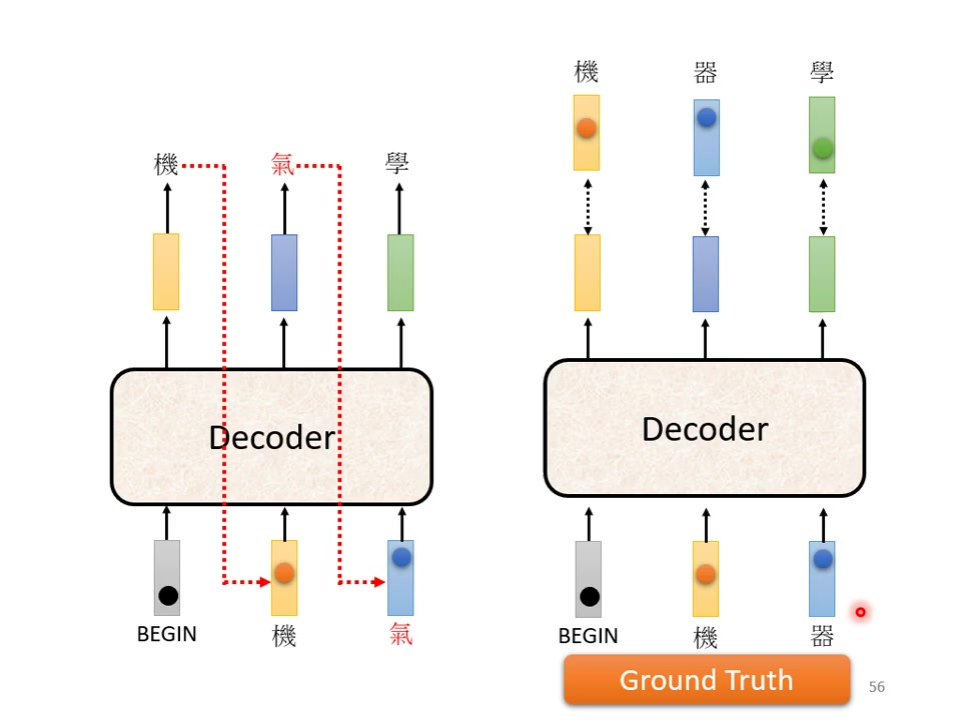
暴露偏差(Exposure Bias):训练时decoder只看到完全正确的输入;
测试时decoder需要处理自身产生的错误输出;后果错误会累积传播,导致”一步错步步错”现象。
解决思路:在训练时有意向decoder输入包含错误的数据定期采样。
Scheduled Sampling:核心思想按一定比例混合正确输入和模型预测输出作为decoder输入。
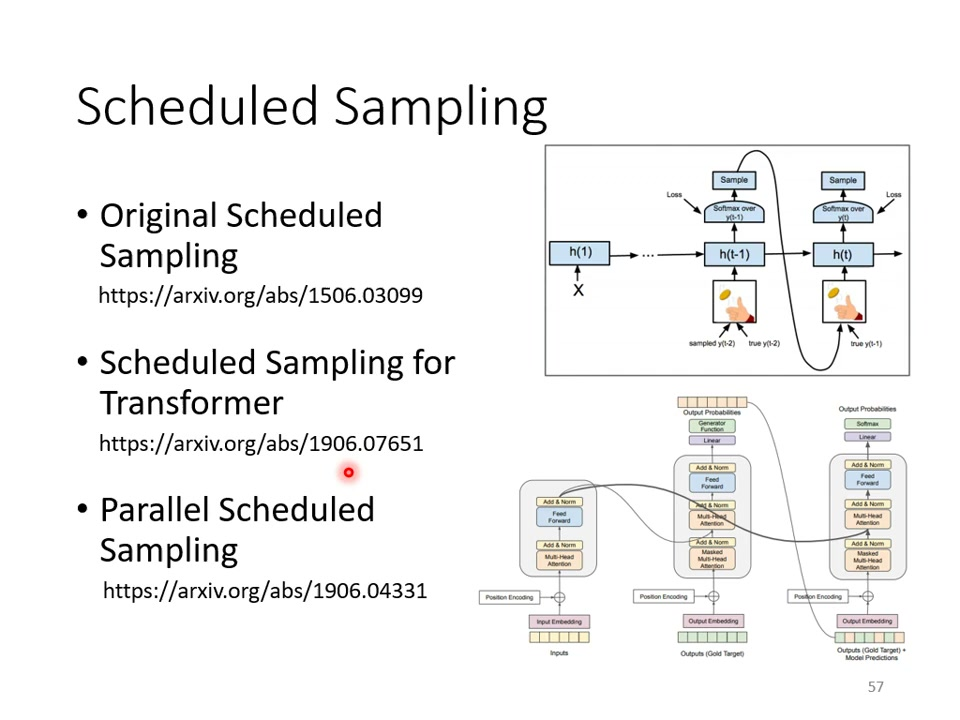
发展历程2015年首次提出用于LSTM;后续有Transformer适配版本(2019年)。
局限性:可能影响Transformer的并行计算能力。
实现变体:Parallel Scheduled Sampling等改进方法;不同网络结构需要采用不同的采样策略;
技术背景:这些训练技巧需要结合Transformer的特殊结构实现;应用范围涉及encoder、decoder及其交互关系的整体优化。