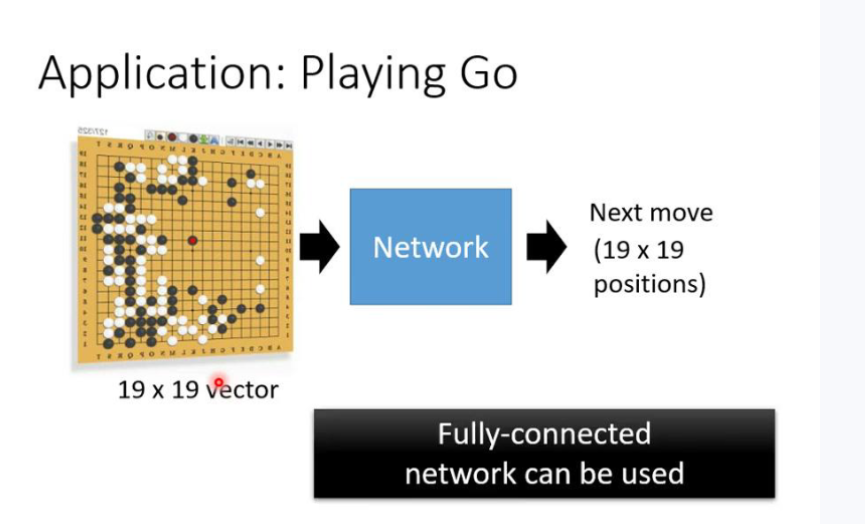
CNN

CNN的主要流程
①规格化图片
在运行训练过程之前们需要将所有的图片scale成大小一样的对应图片,最终cross entropy越小越好,对应的误差也就越小。
模型的输入是对应的图片是一个三维矩阵,对应的前两位是对应的像素点的位置。而第三维是对应的rgb的一个3元数组,经过三维方向的拉直,形成一个可以用来训练的向量集合。
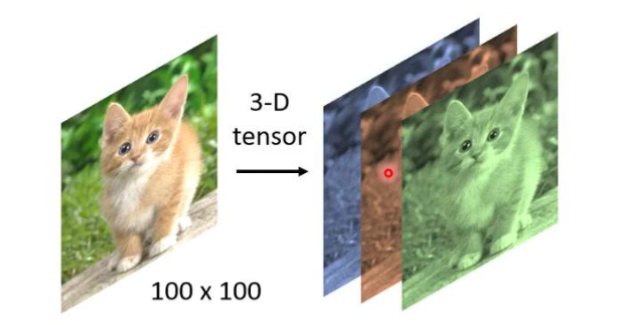
对应的机器和人都是会产生差异的,人和机器都是去寻找对应的图片中生物的特征之后就将这样的特征与人们所熟知的生物特征进行比对,形成结论,但是有可能出现错误。

例如如上的图片,无论是人还是机器都会将其识别成一个鸟类:乌鸦,但是实际上这是一只猫,一只黑猫
②分区
观察自己的小范围去判断特征,这是每一个neuron所作的事情。
将对应的小范围进行拉直,作为输入,之后利用多层的运算形成最终的判断。对应的范围的属性与分布是可以根据实际情况进行灵活调整的。多个范围之间可以进行重叠,亦可以两个神经元去守备同一块的范围,非正方形的范围也是可取的。理论上对应的范围也是可以不相连的。但是实际的图像识别中很难利用的上
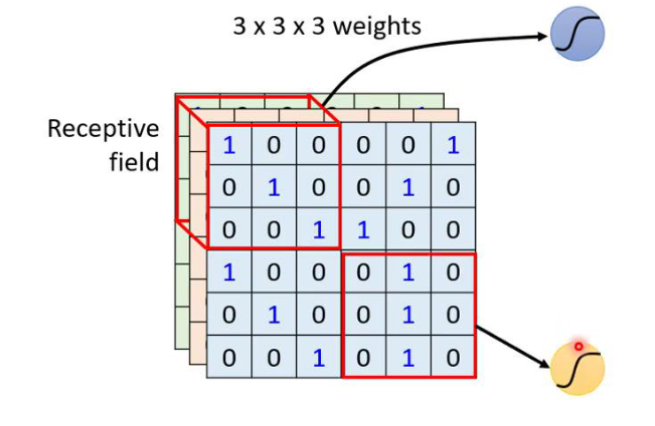
③最经典的设计
对应的所有的channel都参与识别但是对应的小区域的范围很小,每个区域用一个neuron去守备,移动的范围叫做stride也就是步长,对应的步长使对应的每个区域有一个维度的重叠。
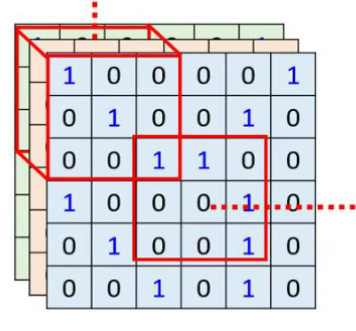
超出对应的图的范围就用零进行补齐(其余的方式也是可取的)按照这种方式去守备整个图片。
④一个小问题
同样的pattern可能出现在图片的不同的位置,但是扫描是无死角的,总是会被探测出来的,不一定所有的区域都要加上对应的部位的检测
解决方法:共享参数,对应的两个神经元的权重矩阵完全相同,由于对应的部位不同,所以对应位置的识别的结果也是客观的。
注意:不能让守备同一块区域的神经元共享参数,会造成相同的结果,没有任何意义。
⑤常见的共享参数的设定方法
不同的参数则代表守备的生物的部位是不同的,对应的参数集合叫做filter,也就是筛选器
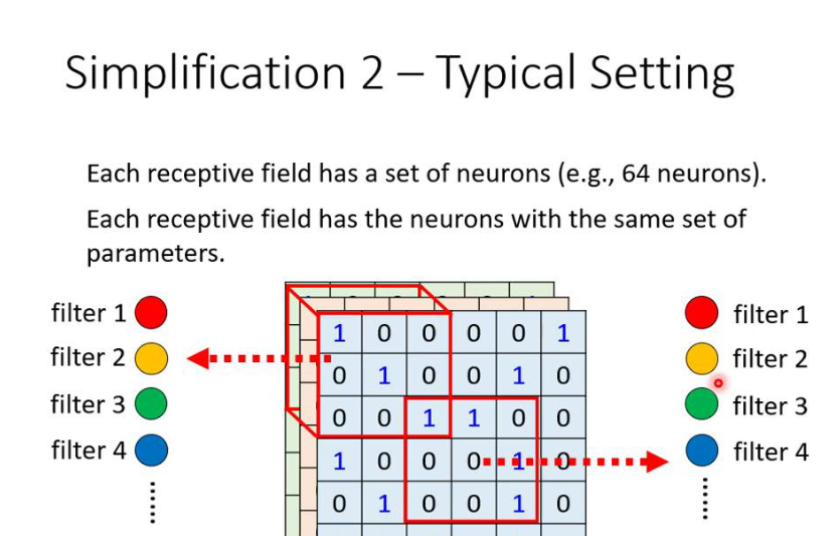
对应的卷积神经网络的优势:
对应的范围越大,对应的弹性就越大,就越容易出现overfitting,过拟合。filter可以利用矩阵相对应位置相乘再加和。
⑥pooling(压缩)
大的图片识别的时候可以压缩成小的图片,本身没有参数,是一个设定好的部件。
Max pooling
分组选择代表,可以选择最大的当代表,卷积神经网络需要与pooling进行交替使用
⑦flatten
会将对应的矩阵进行拉直,判断最终的类别之前需要做这样的动作。
⑧总体流程
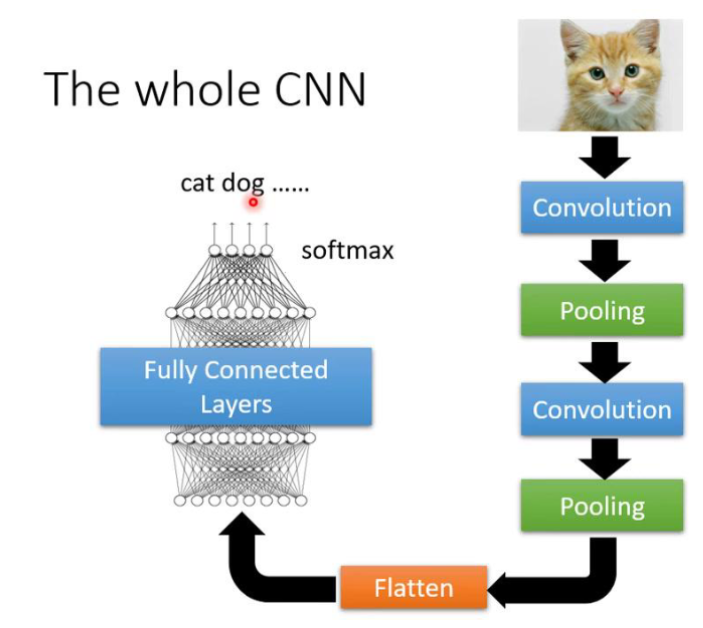
注意:对应的pooling的工作会对最终结果造成影响,但是可以减少计算量。部分的问题是不可以使用pooling的,比如对应的围棋对弈的问题。